Between a few VMworld 2018 sessions and a recent NSX-T Bootcamp, I believe I collected enough information to describe at a high level the new logical routing scheme within NSX-T. The interest is also being driven by an internal project.
The intent is to continue to “route as close as possible to the source” as all routing and switching is being done at the host level in software within the NSX overlay architecture, while the underlay infrastructure provides only transport and external connectivity.
Logical Routers Components
NSX-T has two logical routers components, namely the Services Router (SR) and the Distributed Router (DR). As the names imply, SR is where centralized services are provisioned such as NAT, DHCP, VPN, Perimeter Firewall, Load Balancing, etc., and DR performs distributed routing across all hosts participating in a given transport zone. This is very similar to the Distributed Logical Router (DLR) in NSX-v, except that there is no need for a DLR Control VM or dynamic routing protocols between DR and centralized services.
Apart from the logical router components being named SR and DR, the actual logical router naming convention configured within the NSX-T Manager is “Tier 0” and “Tier 1” router as described further when deploying single or two-tier routing/topologies.
Figure 1 is a conceptual diagram illustrating the SR and the DR placement within the NSX domain, for north-south (external networks) and east-west (internal networks) traffic respectively.
 Figure 1 – Conceptual Design
Figure 1 – Conceptual Design
Single Tier Topology
In a single tier topology, both SR and DR are known as Tier 0 Logical Router. In this architecture, upon creation of a Tier 0 Router with downlink interfaces to logical switches, Tier 0 Distributed Routers are automatically pushed to all Transport Nodes (compute hosts) participating in a transport zone. A Tier 0 DR instance is also automatically added to the Edge Node with the SR, which is instantiated the moment a service is enabled. By default, the link between the SR and the DR uses the 169.254.0.0/28 subnet and is auto-plumbed by NSX-T Manager. A default route is created on the DR with the next-hop pointing to the SR, and the connected routes of the DR are programmed on the SR with a next-hop pointing to the DR.
For east-west traffic, a packet coming from a virtual machine behind a DR to a virtual machine in another logical switch (same or different compute host) is routed at the local DR, same goes for the returning traffic, which is routed at the local DR first. For north-south traffic that traverses the Edge Node, the packet is also routed at the local DR first, and the returning traffic is routed at the local DR residing in the Edge Node before it is encapsulated and sent back to the source.
There is a lot that happens in the background, but from the perspective of the Tier 0 DR router, the logical switches are directly connected as south-bound switches, and the logical switches only see a single logical router or single routing construct upstream. Figure 2 depicts the physical and logical view with color-coded routers to indicate which one is SR, which one is DR within a single tier topology.
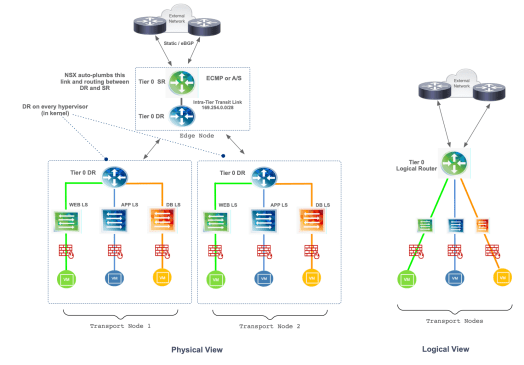
Figure 2 – Single Tier Topology
Two-Tier Topology
In a two-tier (or multi) routing topology, the fundamentals of SR and DR remains the same, but the logical routers are named Tier 0 and Tier 1 routers and both are instantiated on the hypervisors of each transport node in a fully distributed architecture. The “RouterLink” between Tier 0 and Tier 1 routers is automatically configured with a /31 IP in the subnet range of 100.64.0.0 when the Tier 1 is connected to the Tier 0 router, same auto-plumbing process in the backend by NSX-T Manager. There is no routing protocol running between Tier 0 and Tier 1 routers. The NSX management plane knows about the connected routes on Tier 1 and creates static routes on the Tier 0 router with a next-hop in the subnet range of 100.64.0.0/10.
As with the single tier topology, the Edge Node also has instances of SR and DR locally, or Tier 0 and Tier 1. The major difference is that even though Tier 1 is being “distributed” across all Transport Nodes, it has tenant isolation from the other Tier 1 routers across the NSX domain. A Tier 1 can be removed from the environment without affecting any other tenant, completely independent (or isolated) given the multi-tenancy nature. Specific services can also be enabled on a Tier 1 router such as Load Balancing or NAT.
If there is a need for inter-tenant connectivity, traffic between tenants traverse the local Tier 1 as well as the Tier 0 routers in the transport node, and packets are routed locally by the Tier 1 before it hits the wire via Geneve encapsulation. Returning traffic is also routed at the local Tier 1 at the remote tenant. For north-south traffic that traverses the Edge Node, the packet is also routed at the local Tier 1 first, and the returning traffic is routed at the local Tier 0 and Tier 1 instantiated at the Edge Node.
Figure 3 depicts the physical and logical view with color-coded routers to indicate which one is Tier 0, which one is Tier 1 within a two-tier topology contained in each tenant.
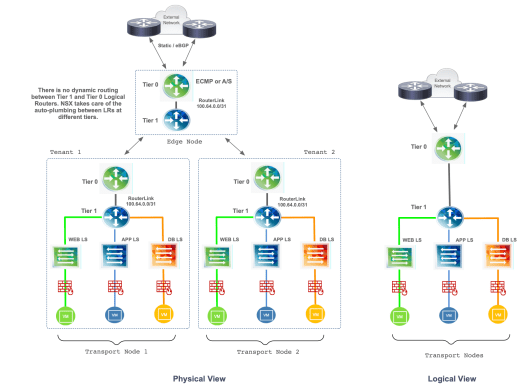
Figure 3 – Two-Tier Topology
Which One?
The decision of when and which topology to use will come down to business requirements. In a multi-tenancy environment, of any kind, two-tier routing has its place by providing tenant isolation and independent control over network and security policies. For some, it may simplify management, while for others, it may add complexity. The single tier topology is as “simple” as it could be. If there is no interest (or requirement) in separating routing domains for tenants/groups, then only Tier 0 can be deployed.
Recommended Sessions
These are the VMworld sessions which add more in-depth details with packet walk of the logical routing in NSX-T:
- NET1127BU: NSX-T Data Center Routing Deep Dive
- NET1561BU: Next Generation Reference Design with NSX-T Data Center (part 1)
- NET1562BU: Next Generation Reference Design with NSX-T Data Center (part 2)
Credit
Thanks to my friend @LuisChanu who provided invaluable inputs and guidance.


 At first, one may think this is about automating a network or any kind of API-driven device with the intent to eliminate repetitive tasks, and not necessarily a business process or workflow. Well, at least this was my first thought when I heard about
At first, one may think this is about automating a network or any kind of API-driven device with the intent to eliminate repetitive tasks, and not necessarily a business process or workflow. Well, at least this was my first thought when I heard about 




You must be logged in to post a comment.