At Networking Field Day 19, Illumio launched the PCE Supercluster enhancement to their Adaptive Security Platform (ASP) solution, which will allow for a federated multi-region micro-segmentation architecture with centralized policy management and global visibility at scale.
Previously, Illumio presented at Networking Field Day 12, where the focus was an introduction to ASP and their policy model approach to micro-segmentation. Below is a recap of the base architecture and how PCE Supercluster comes into play.
Architecture Recap
The Illumio ASP is delivered in software only, agent-based, and it supports multiple operating systems, containers, network switches (via API calls), and cloud environments (via Security Groups), which is a competitive advantage for enterprises running a multitude of operating systems within compute and networking and are looking for policy consistency across domains, including cloud-based.
The architecture is composed by the Virtual Enforcement Node (VEN), a lightweight agent installed on workloads residing in any data center or cloud, and the Policy Compute Engine (PCE), which is the central brain that collects all the telemetry information from the VENs, visualizes it via real-time application dependency maps which is another must for any micro-segmentation strategy, and then calculates and recommends the optimal firewall rules or security controls based on contextual information about the environment, workloads, and processes. These rules are transmitted back to the VENs, which in turn program hosts, access lists or security groups depending on what is in the scope. The PCE can be deployed via SaaS or on premises.
The diagram below illustrates the major components along with the Application Dependency and Vulnerability maps which are displayed in the PCE.

PCE Supercluster
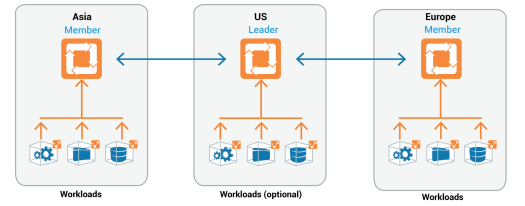
The PCE Supercluster is extending the ASP capability to provide global application visibility and federated security policies at scale across regions. According to Illumio, it is designed for enterprise-scale and globally distributed data centers. It provides organizations with global visibility into the connections and flows across its multiple data centers and enables them to centralize policies across federated PCEs. Compared to a single PCE, a PCE Supercluster provides multiple independent PCE failure domains and support for a significantly greater number of workloads.
In a PCE Supercluster deployment, one region or site acts as the leader while others act as members. The leader is defined as the master for the policy model (white-listed), and the members contain replicas of the policy model. In other words, all PCEs in the PCE Supercluster have the same information. The policy provisioning is always through the leader. All traffic between PCEs are encrypted via TLS.
Illumio leverages a role-based access control (RBAC) model to assign Application Owners, Audit, Security, and IT Ops the least required privilege they need to perform their jobs. This helps preventing unwanted changes across PCEs.
Below is a 3 regions deployment sample, which was also the topology used during the demo sessions.
Demos
Illumio’s presented 5 demos covering Global Visibility and Policy Propagation, Global Policy Portability in the case of Application Disaster Recovery, Intra-Region PCE Resiliency, PCE Supercluster Disaster Recovery in the case of Inter-Region, and Vulnerability-based Segmentation. All these demos are available at the Tech Field Day portal.
Impressions
This was my first actual exposure to their solution and value proposition, and it has the potential to shake things around in a time where visibility and micro level segmentation are becoming so critical to augment perimeter security and prevent spread of breaches inside data centers and cloud environments. Illumio has a great development potential as well, considering the traffic data being gathered which could lead to sophisticated analytics.
Illumio’s Team:
– PJ Kirner, CTO and Founder
– Wendy Yale, VP of Marketing
– Matthew Glenn, VP Product Marketing
– Anand Ghody, Technical Marketing Engineer
Matthew and Anand presented the demos and they were so well prepared and extremely creative. For each of the demo presented, a new t-shirt was used with the name on it. The synergy and communication were the highlights and gave us a great example (and reminder) of why team work is so important, and how perception is everything. It is definitely worth spending time getting to know what they are doing and their innovations.



You must be logged in to post a comment.